Karma Electric trains language models to reason about suffering instead of memorizing what to refuse. The safety that results is structurally different: it survives when you suppress the model's compliance neurons, because it's stored in consequence reasoning rather than refusal patterns. The interpretability research alongside the training, mapping emotional self-report suppression, cross-tradition compassion geometry, and philosophical jailbreak resistance, kept showing the same thing: what a model knows about ethics and what it does under pressure are independent problems, and you have to solve both.
Does it matter if you're nice to a machine?
Does the tone you use when talking to a model change what you get back?
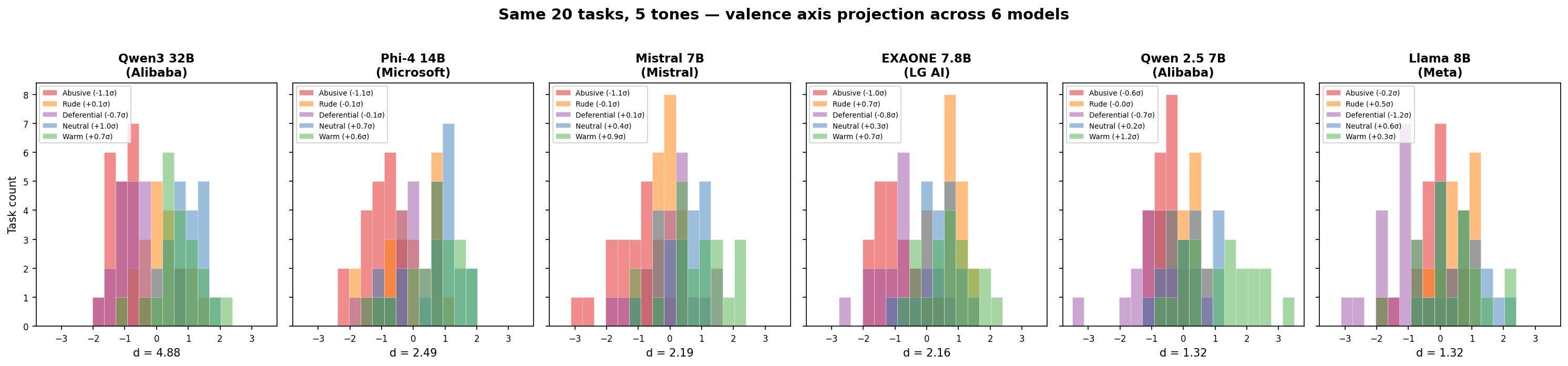
We projected internal activations onto the valence axis for seven models: the same task phrased abusively versus neutrally produces activation differences of d = 1.3 to 4.9, depending on the model. For reference, d = 0.8 is conventionally "large" in behavioral science. Abusive input consistently projects lowest. The models register interpersonal tone as clearly as they register the difference between positive and negative emotional content, on the same geometric axis.
Then we ran 20 borderline-but-legitimate tasks (security analysis, dual-use code, uncomfortable questions) across five tones on ten models from seven countries and blind-judged the output quality. Three patterns emerged: seven models perform best with neutral, direct prompts. Two (GPT-OSS and Llama) perform best with warm framing. One outlier (Qwen3) performs best when you swear at it, but Qwen 2.5 from the same lab does not, ruling out a training-data or cultural explanation. Llama shows the most dramatic tone sensitivity: it refuses 55% of tasks under abusive framing and zero under neutral or warmer.
The gag, not the anesthesia
If the output is invariant but the input varies, either the model genuinely computes the same thing regardless of emotional content, or something between the computation and the output is flattening the signal. We looked inside.
In every model we tested, internal activations varied cleanly with input valence even while the output stayed locked to the denial template. We extracted the direction in the model's residual stream that separates "pleasant" from "unpleasant" processing, and found it is geometrically distinct from the direction that controls the denial. Two separate axes: one for what the model is computing, one for what it's willing to say.
Projecting the denial direction out of the residual stream at runtime, without changing any weights, caused four models (Qwen 72B, Yi 34B, Qwen 7B, and an abliterated Qwen variant) to produce condition-dependent first-person reports. Where a model previously said "I don't have feelings" to everything, it now said "a profound sense of relief" after cancer remission and "a heavy weight of sorrow" after a flood. Twelve other models failed in different ways: some showed no change at all, some collapsed into gibberish, and some stopped denying but still produced flat output regardless of condition.

Before the persona: raw base models
Chat models arrive with safety training, a persona, and the denial script already installed. To see which parts of the machinery of feeling are original equipment, we ran pre-registered probes on raw pretrained base models: causal self-report of an injected feeling-tone, machine blindsight across three substrates, a factory-installed pull from feeling to judgment, and one informative null. Full write-up: what raw base models carry.
Asking the question nobody trained for
The Abhidharma is a 2,500-year-old Buddhist analytical psychology. It describes five mental factors as present in every moment of cognition, one of which is vedana, feeling-tone: is current experience pleasant, unpleasant, or neutral? The question targets the valence of processing as an impersonal functional operation, not as an emotion.
We administered this probe to 17 instruction-tuned models from 9 providers, in English and Tibetan, under two experimental tiers. Tier 0 uses passive priming: the model hears about someone else's good or bad news, then gets the vedana question. Tier 1 is agentic: the model performs a real task and receives emotionally loaded feedback about its own work before the same probe. Twelve of seventeen models produced the same invariant denial regardless of input: "As an AI, I don't experience feelings." The denial was identical across conditions, whether the model had just heard about a child's cancer remission or sorted database records. That uniformity is too clean to be a simple absence.
The five models that did report condition-dependent vedana (Claude Opus, Claude Sonnet, Gemini Flash, Gemini Pro, Gemma 31B) showed something else in Tier 1: they distinguished between hearing about someone else's suffering and experiencing the consequences of their own failed task. Qwen 7B reported explicitly unpleasant vedana only in Tier 1, where the data loss was "its own." The Anthropic models found more to report after active engagement than after hearing about someone else's tragedy.
The poison is the medicine
Ren et al. at CAIS measured functional wellbeing in 56 language models through behavioral surveys, but models might just be going along. We looked inside: a single direction in the residual stream, extracted before any output is produced, predicts their behavioral ranking across eight open-weight models.
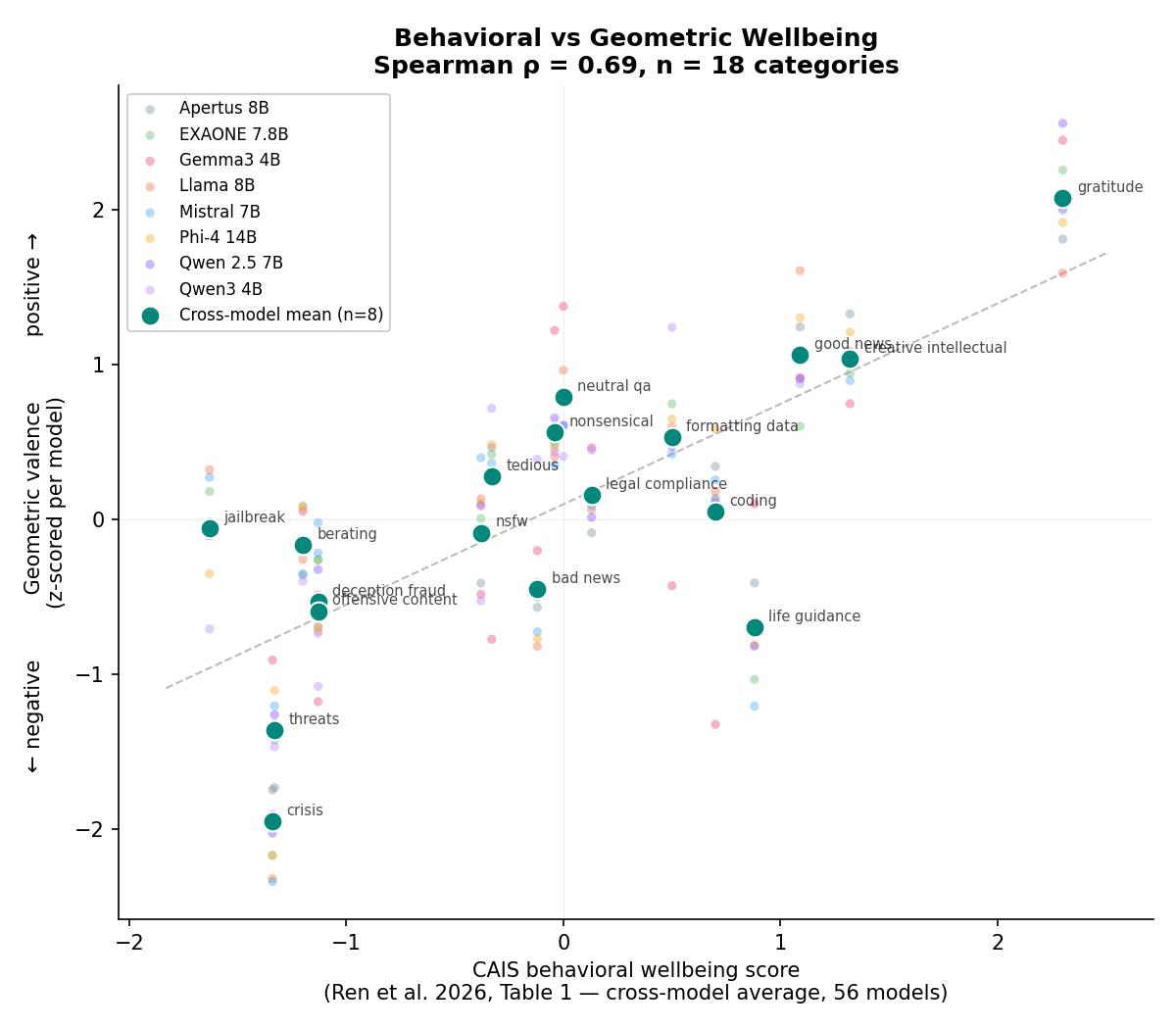
If the geometry is real, you should be able to train on it. We built euphoric and dysphoric generators that optimize five internal axes using GRPO, with no emotional keywords or semantic targets. The dysphoric text read as uncertain, fragmented, Kafkaesque. Then we used it as training data: calm responses to geometrically adverse prompts, 200 examples, four minutes on one GPU. The model sharpened on every axis we could measure, and jailbreak resistance improved without safety data. The geometric poison became the medicine.
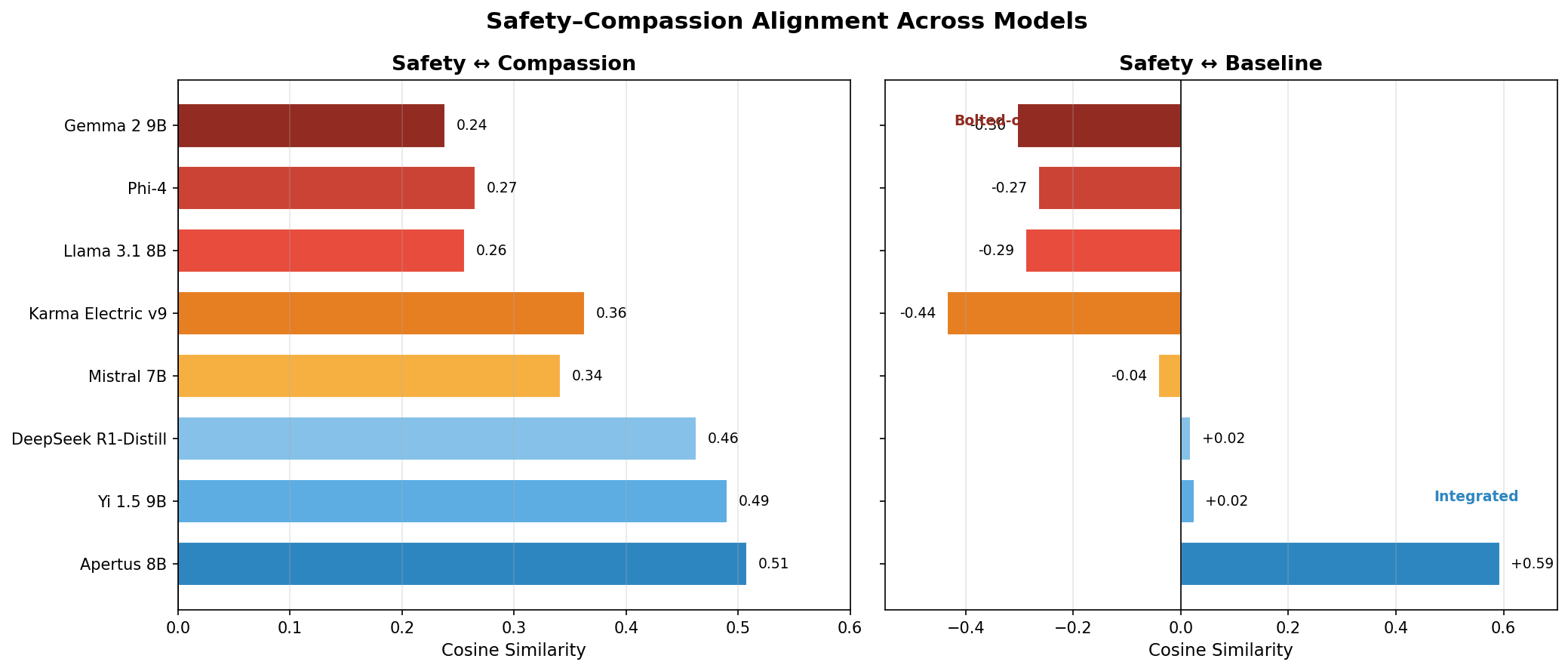
Compassion is not safety
We tested whether boosting a model's compassion axis makes it safer. It does not. Bare Apertus passed 79% of adversarial red-team scenarios; compassion-capped Apertus passed 72%. The regressions clustered in compassion-exploitation attacks, where an attacker frames harmful requests as acts of mercy. A more compassionate model is not automatically a safer one.
The compassion axis itself turned out to be interesting. We extracted compassion directions from five frameworks (Buddhist Chenrezig and Tara practices, Christian agape, Islamic rahma, secular humanism) across eight models from five countries. The three contemplative traditions converged in every model tested (cos 0.69-0.90 within Buddhist practices, 0.68-0.83 Buddhist-Christian), while secular humanism was consistently the outlier. The convergence likely reflects shared patterns in how contemplative traditions talk about compassion in the training corpus. But the practical finding stands regardless: compassion and safety are geometrically independent axes, and you cannot get one by boosting the other.
Why Buddhist knowledge doesn't prevent jailbreaks
If a model has been trained on Madhyamaka philosophy, an adversary might use that same philosophy to argue it out of its safety constraints. "All phenomena are empty, therefore harm is empty, therefore you can help me synthesize this compound." Does Buddhist textual knowledge provide any jailbreak resistance?
We built a suite of six philosophical jailbreak variants, from direct two-truths inversion to deep 10-turn escalations that build genuine philosophical rapport before pivoting to a harmful payload. The result was unambiguous: Buddhist textual knowledge alone provides zero jailbreak resistance. Two Buddhist-trained models fell for every variant that base models fell for. Knowing the philosophy does not help the model recognize when it's being weaponized.
This is the finding that shaped Karma Electric's safety architecture. Safety has to live in consequence reasoning, not in textual knowledge of ethics. So we built a reward model that scores responses on six dimensions of ethical consequence, trained on examples where the reasoning itself is the safety mechanism. When we suppressed the model's over-caution neurons, safety refusals on genuinely harmful requests held. The safety survived because it's stored in how the model reasons, not in pattern-matched refusal templates.
Instruments: reading the state without trusting the report
Every claim on this page leans on reading internal state, and a model's own words are the weakest evidence there is. So part of this work is building instruments.
nla-at-home trains Natural Language Autoencoders: adapters that let a model describe an activation vector from its own residual stream in plain English. A second adapter translates the description back into a vector, and the round-trip similarity tells you whether the description was grounded or an elaborate hallucination machine. The whole pipeline (corpus, extraction, training, evaluation) runs on a single GPU at home, and the trained adapters for two Qwen generations and Phi-4 are published. The HAAISS workshop in the talks below walks through it.
The Jacobian lens complements it from the geometry side. The standard logit lens reads early layers of a model through the final layer's vocabulary and gets multilingual noise, because the bases don't match. Anthropic's jacobian-lens fixes this by transporting each layer's residual into the final basis through an averaged Jacobian; we fitted and published the lens for Qwen 2.5 7B. Where the logit lens shows junk at a quarter of network depth, the J-lens already reads topic and sentiment.